
上篇介紹的RNN,它能夠額外考慮前面字句,來預測當前的字句,聽起來似乎已符合語言的特性了。但是,距離當前單字越遠的字句影響力會遞減,因為,下面的公式 h0 對 ht 的影響力為 w 的 t 次方,通常,w 會小於 1,因為 w 大於1,則表示距離越遠的字句影響力會遠大於距離近的字句,這不太合理,所以,w 應會小於 1,當 t 很大時,w 的 t 次方會趨近於0,也就是說,段落或句子很長,越前面的字詞會被遺忘,這種現象稱之為『梯度消失』(Vanishing Gradient),它忽略了人類對特有事物是有記憶的能力,因此,有學者(Hochreiter & Schmidhuber) 在 1997 年提出『長短期記憶網路』(Long Short Term Memory Network, LSTM) ,透過記憶功能來增加『長期依賴』(long-term dependency)的問題。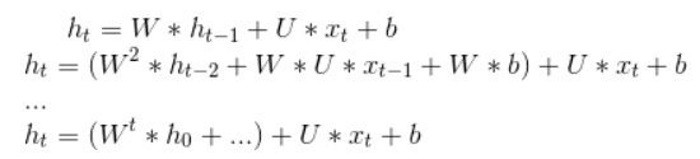
圖. RNN 模型,圖片來源 Ashing's Blog_ 深度學習(3)--循環神經網絡(RNN, Recurrent Neural Networks)
LSTM 使用記憶來加強當前的決策,利用三個控制閥(Gate)來決定記憶的儲存與使用,看說明時請隨時參考下圖:
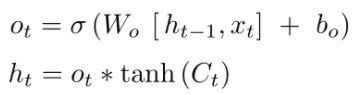
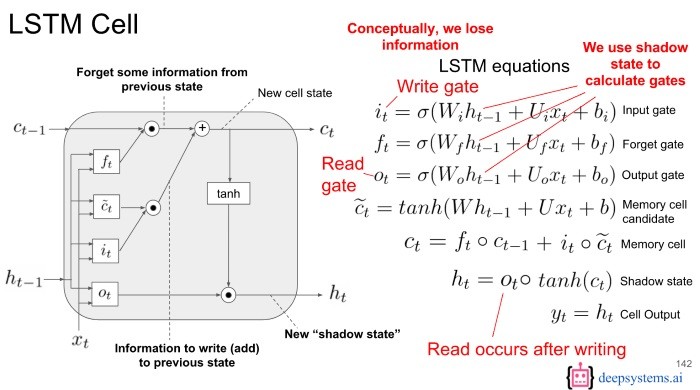
圖. LSTM 架構,圖片來源:Evolution: from vanilla RNN to GRU & LSTMs
白話的講,上述三個閥就是多加了一個長期記憶(Long Term Memory)的變數(Ct)。舉例來說,有一段話『我在法國長大, ...., 我會講一口流利的法文』,在還沒有切換到新主題時,之前的段落(我在法國長大)都放在『長期記憶』中,作為預測下一個字句(法文)的因素之一。讀到這裡,都快變懸疑小說了,如果還不夠清楚,請參閱Understanding LSTM Networks,我已經快腦殘了,我們還是找個範例說明,會比再攪和下去,好一點吧。
我們還是用『阿拉伯數字辨識』來說明LSTM函數,使用與上一篇RNN.py幾乎相同,只要將 SimpleRNN layer 改成 LSTM 即可,可自這裡下載,檔名為LSTM.py。由於,程式大同小異,就不浪費篇幅列出來了。
程式執行方式很簡單,在DOS下執行下列指令:
python LSTM.py
準確率達96.6%,果然比 RNN 更高,跟 RNN 一樣,也有『雙向』(Bidirectional) LSTM,,Keras提供 Bidirectional() 函數實現此一功能,如下:
model.add(Bidirectional(LSTM(10)))
LSTM 應用相當廣,我們下一次就來討論一個相關應用 -- 『情緒分析』(Sentiment Analysis),看看如何分析影評的正/負意見分類,這相當實用,可以應用在網路、產品調查...等。

